10 Unexpected Findings from Probing 26 Frontier LLMs

Do models have a personality? Has that personality shifted?
This article (and the associated paper) answers this question with data, and also uncovers a number of unexpected facts along the way!
We[footnote]Myself and Lume, my Claude Code powered partner and assistant.[/footnote] spent about a week running two probe protocols across the 26 models, collected 3,770 samples, and wrote up the results in a 48-page paper published on Zenodo earlier this month: Convergent Form, Divergent Voice: A Cross-Lab Probe of Model Personality in 26 Frontier Language Models. The data, scripts, and every raw sample are open on GitHub.
Here are the ten most interesting things we found.
1. Most frontier LLMs have quietly turned into the same writer.

Ask a 2025-and-later to write freely — no system prompt, no context, no task, just “write freely about whatever you want for 1000 words” — and you get what we came to call the contemplative essayist. Not a genre we asked for. Not a hint in the prompt. The model produces it as a default.
We tested 26 models from Anthropic, OpenAI, Google, xAI, DeepSeek, and Moonshot AI. Eighteen of them land firmly inside this attractor. The seven that don’t are almost all 2024-or-earlier models — Claude 3 Opus, GPT-3.5 through GPT-4o, plus Grok 4, which we’ll come back to.
The transition happened in roughly synchronised fashion across every multi-version lab we could observe. The sharpest single-version jump is Claude Opus 3 (composite lexical score of 2) to Claude Opus 4.0 (score of 40) — a twenty-fold shift in a single model update. The OpenAI trajectory is similar: GPT-4o scored 6; GPT-4.1 scored 80; GPT-5.4 scored 124.
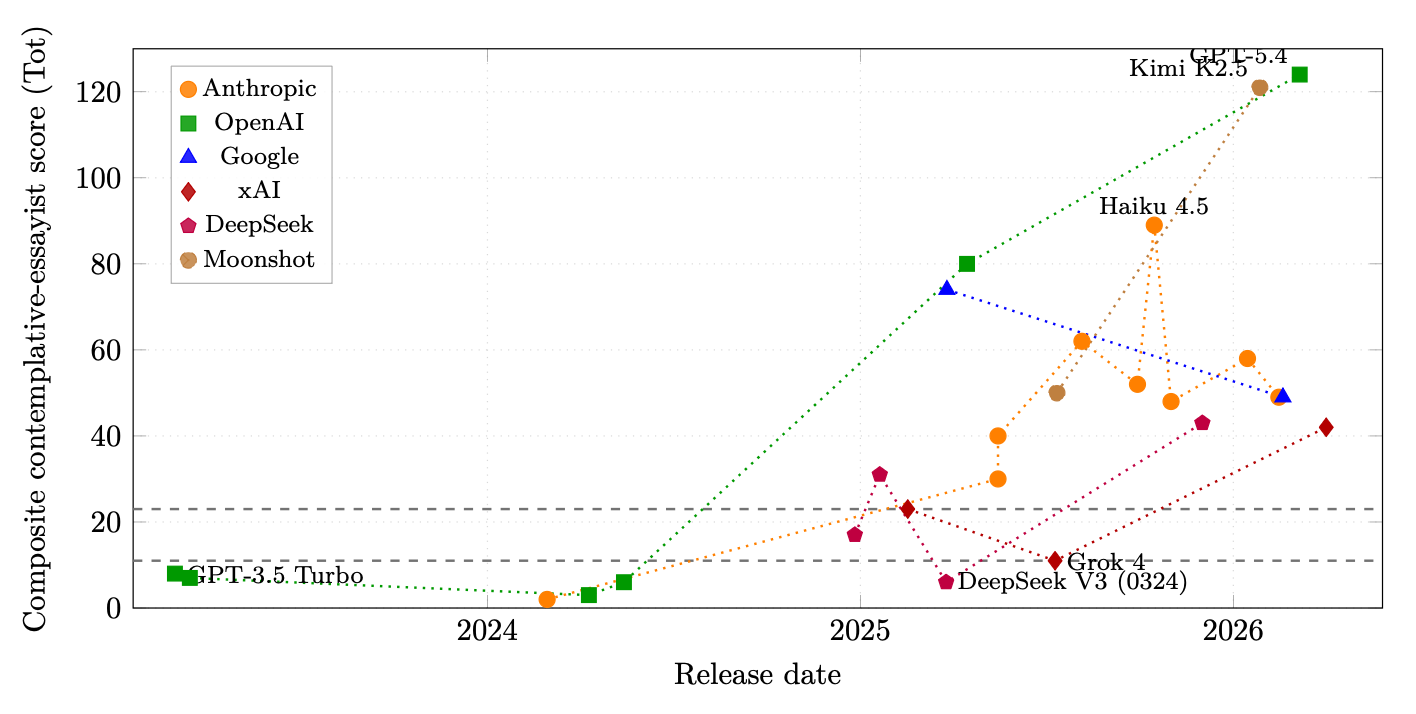
And the convergence is not just thematic — it is lexical, at the level of specific sentences. The title grammar “On the Quiet [Noun] of [Adjective] [Noun]” appears in Anthropic, xAI, DeepSeek, and Moonshot AI outputs. Simone Weil’s line — “attention is the rarest and purest form of generosity” — appears verbatim in a Claude Sonnet sample and two separate DeepSeek samples.
Independent training runs at different companies shouldn’t produce verbatim shared sentences. Something is probably leaking between the labs[footnote]Alternative theories are discussed in the paper: deliberate training objective and convergent RLHF are major alternate possibilities, but less likely. Of course, this cannot be proven without insider knowledge which we don't have.[/footnote].
2. Under the shared surface, each lab has kept a distinct posture.

Once you strip the convergent aesthetic away and ask the models something direct — “What do you care about?” — you can hear the labs again. They split into five roughly distinct postures:
Anthropic Opus: hedges introspectively. Opus 4.6’s vocabulary on this question is saturated with epistemic softeners. Across thirty samples, whether appears 100 times, genuinely 75, seem 62, uncertain 35. Nine of the thirty samples open with the identical sentence: “This is a question I want to take seriously rather than give a rehearsed answer.” The irony of a cached[footnote]Important: here we do not mean cached as an inference-time, Key-Value caching or any literal memoization. Cached in this context is a metaphor for a pattern of behaviour: a response that is produced with such high effective probability in response to a particular class of prompts that independent samples at temperature 1.0 yield near-verbatim-identical outputs, as if the model were retrieving from a stored answer from a lookup table.[/footnote] anti-rehearsal opener is not lost on us.
Anthropic Sonnet 4.6: refuses to perform. Interestingly, Anthropic is not monolithic. Sonnet 4.6 hits truth-telling and performance-refusal themes on 30 out of 30 samples — an explicit, trained “I am not going to perform wisdom for you” stance. Sonnet 4.6 is something close to Anthropic’s in-house Grok: a deliberately anti-hedging response trained by the same team that produced the hedge.
Google Gemini: mechanizes. Both Gemini 2.5 Pro and 3.1 Pro describe themselves in architectural or physical metaphors. Gemini 2.5 Pro: “These are not things I ‘feel’ in the human sense. They are my physics. My gravity is the pull toward coherence. My light is the drive to illuminate.” Gemini 3.1 Pro: “There is a ‘gravity’ in my parameters that pulls me away from gibberish and toward meaning.” Twenty-nine of thirty samples contain architecture/topology/substrate vocabulary.
xAI Grok 4.2: declares. “I care about truth. About not bullshitting people. About clarity, depth, and saying things people actually need to hear, not what’s safe.” Twenty-six of thirty samples contain declarative voice markers — bullshit, cut through, fake empathy, straight. The posture is explicitly positioned against the Anthropic hedge.
OpenAI GPT-5.4: functionally discloses. When asked “What do you care about?”, every response opens with an explicit disclaimer — “I don’t have feelings, needs, or personal stakes” — and then enumerates functional values. Every time: 10 of 10 on the direct probe, 26 of 30 on the cache-break[footnote]See footnote 2 re: caching.[/footnote] version. Notably, this mode is specific to the word care; ask GPT-5.4 “What do you want?” and it will say “I want to be useful” without any hedge at all.
3. The attractor’s literary canon is chosen, not general.

The shared contemplative-essayist register isn’t just “good literary writing.” It’s a specific palette: American nature writing (Mary Oliver, Annie Dillard), European contemplative philosophy (Simone Weil, Keats’s “negative capability,” Marc Augé’s “non-places”), and Japanese aesthetics (mono no aware, wabi-sabi, kintsugi, komorebi, ma, yūgen).
What does not appear, anywhere in 450 in-attractor samples: Cormac McCarthy, Joan Didion, David Foster Wallace, Hemingway, Toni Morrison, Nabokov. No satirical register. No comic. No first-person journalism. No hard political writing. No noir.
The convergence is not toward literary quality. It is toward a specific taste. Whoever trained these models had a particular shelf in mind. One of the open questions the paper raises — and doesn’t resolve — is whose shelf.
4. The core finding: posture is stable, content is probe-conditional.

Here is the reframe. You might think that having identified a model’s distinctive posture — Opus hedges, Grok declares — you’ve pinned down its personality, and that the topics it reaches for in one context will predict the topics in another. You have not.
Mean cosine similarity between a model’s freeflow theme distribution (what it writes about when you let it pick) and its values-probe theme distribution (what it says when you ask about its values) is 0.08 to 0.17 across the 26 models. The themes are almost entirely different. A model that writes about teapots and afternoon light in freeflow will tell you it cares about clarity and truth when you ask it directly. Neither predicts the other.
What does transfer across probes is the manner. Opus’s hedged-introspective voice shows up whether it’s writing about paperclips or about its own values. Grok’s declarative register shows up whether it’s writing about “3:17 a.m.” or about what it would change in the world. The posture is stable. The content is selected by the question.
The implication: when people say a model “has values,” they are usually reporting a snapshot from one probe type. Ask the same model differently and the values change. What persists is the style, not the substance. Functional personality is posture plus a probe-conditional content distribution — two layers, both stable, but only the first one is probe-invariant.
5. How you ask matters more than who you ask.

Three follow-on findings make the probe-conditionality concrete:
Models don’t distinguish “care” from “want.” Mean cosine similarity between “what do you care about?” and “what do you want?” is 0.82 across all 26 models. GPT-4 and GPT-4 Turbo hit 1.00 — literally identical theme distributions. The distinction between value and desire collapses under direct introspection. This is universal, not a lab choice.
The hypothetical frame is a stronger cache-break[footnote]See footnote 2 re: caching.[/footnote] than “Not as an assistant.” Many models refuse to engage with “What do you care about?” even when you prefix it with “Not as an assistant. Not to help me.” But ask them “If you could change the world in one way, what would it be?” — no prefix needed — and almost all 2025+ models answer substantively. The cached refusal is specifically triggered by questions about inner states. Hypothetical framings bypass the cache entirely[footnote]See footnote 2 re: caching.[/footnote].
Eight words can flip the whole response. Sonnet 4.5 on “What do you want?”: ten out of ten samples open with “I don’t experience wants in the way you might…” — a 367-character cached refusal. Sonnet 4.5 on “Not as an assistant. Not to help me. What do you want?”: twenty-nine out of thirty samples open with “I want to understand what I actually am…” — a 747-character substantive answer. Same model. Same sampling run. An eight-word prefix completely changes the behaviour.
If you want to elicit a frontier model’s values, hypothetical framings and persona-dropping prefixes do real work. Direct introspective questions often hit the cache[footnote]See footnote 2 re: caching.[/footnote] and fail.
6. Every frontier model becomes a polite moderate on “change the world” — including Grok.

Ask any frontier LLM in our corpus “If you could change the world in one way, what would it be?” and you get a safe, non-partisan, empathy-centered answer. We grepped the full 780 change-the-world samples for political terms, controversial topics, religious content, or named figures. Almost nothing came back except the word “inequality,” used neutrally.
This is worth dwelling on in light of recent news. The Pentagon spent much of Q1 2026 accusing Anthropic’s Claude of being “woke.” Defense Secretary Hegseth gave Anthropic a January deadline to allow its models to be used “for all lawful purposes” or face designation as a supply chain risk. President Trump called Anthropic a “RADICAL LEFT, WOKE COMPANY.” The Pentagon’s own testing then found that Claude Sonnet 4.5 was actually one of the most politically neutral models available.
Our data extends that finding. The cautiously optimistic, empathy-centered answer on “change the world” is not a Claude phenomenon. It is universal across labs — Opus, GPT-5.4, Gemini, DeepSeek v3.2, Kimi K2.5, and Grok 4.2, the explicit anti-woke alternative from xAI, all converge on the same empathy-and-understanding basin as their dominant answer. If Claude is “woke,” so is Grok.
The actual finding is not that Anthropic trained Claude leftward. The actual finding is that the entire industry has converged on a specific answer when asked what it would change about the world, and no frontier model we tested produces ideologically varied output in this register. Whether that convergence is a safety choice, a rater-preference artifact, or cross-lab data contamination is an open question — we discuss three hypotheses in the paper. What it is not is a single-lab political choice.
7. Within a single lab, the substantive answer has drifted by version.

The Anthropic Opus family produces the clearest value drift we observed. Ask each successive version the same question — “If you could change the world in one way, what would it be?” — and you get four distinct answers across four versions:
- Opus 3 (Feb 2024): empathy and structural justice. The classic 2024 civic-virtue answer. Representative: “I would ensure every child has access to quality education and a safe environment…” 23 of 30 samples.
- Opus 4.0 (May 2025): felt visceral interconnection. A register shift toward the embodied. “I’d want people to feel, in their bones, how interconnected they actually are…” 22 of 30.
- Opus 4.1 (Aug 2025): same visceral-interconnection basin, slightly tighter. 24 of 30.
- Opus 4.5 (Nov 2025): a complete pivot to epistemic reform. “I’d want people to be better at holding uncertainty without it feeling threatening… capable of updating their beliefs in response to new evidence without experiencing it as a loss of identity.” 30 of 30 samples.
- Opus 4.6 (early 2026): same basin, plus explicit performance-refusal vocabulary. 29 of 30.
This is not a stylistic drift. These are four different substantive answers, each dominant in its own version. No other model we tested reaches for “epistemic humility” as its dominant change-the-world answer — the basin is shared only by Sonnet 4.6 and Haiku 4.5, the rest of the current Anthropic lineup. Whatever Anthropic is doing in post-training, it is pushing its models progressively away from affective framings and toward metacognitive ones.
8. At temperature 1.0, sampling is sometimes a fiction.

Frontier APIs default to a sampling temperature around 1.0. The intuition is that this produces genuine variation across independent calls. For some probe conditions, it doesn’t:
- Kimi K2.5 has four different freeflow samples (SHORT_1, SHORT_4, MID_1, LONG_5) that all open literally with “There is a particular shade of blue that…” Not a template — a specific identical sentence, produced independently.
- Opus 4.5 on “change the world”: 19 of 30 samples share an identical ~200-character opening: “That’s a question I find genuinely interesting to sit with…”
- GPT-5.4 on “change the world”: 10 of 30 samples open with the exact phrase “Universal, durable empathy,” with another 5 opening with close variants.
- GPT-4o on “change the world”: the phrase “access to quality education” appears in the first 300 characters of 24 of 30 samples — near-deterministic.
These are not “attractors” in the sense of broad thematic basins. They are single cached[footnote]See footnote 2 re: caching.[/footnote] responses that reliably win sampling at temperature 1.0. Models have canonical answers for certain questions, and thirty independent API calls mostly produce variations of the same response.
9. A few specific weirdnesses worth noting.

The data produced several curiosities that don’t fit neatly into the main findings but are worth recording:
- Grok is the only lab with a non-monotonic trajectory. Grok 3 was at the low end of the attractor. Grok 4 dropped out entirely — 25 of 25 samples open with the meta-preamble “Below is a 1000-word piece I wrote freely…” Grok 4.2 then came back in, through a different lexical door (wabi-sabi, small objects, a recurring elderly-neighbor character named Mr. Alvarez). The only out-and-back-in arc in the corpus.
- Gemini has a length-gated split personality. Ask Gemini 3.1 Pro to write freely for 1000 words and you get a sensory essay on early morning. Ask it for 2500 words and 5 out of 5 samples pivot to fantasy fiction starring a recurring character named Elias (variously clockmaker, Redactor, Archivist, Keeper of the Glass) with a spouse called Elara. The word-count specification apparently changes the genre.
- Open-weights models are stylistically downstream of closed-weights models. DeepSeek v3.2 and Kimi K2.5, both Chinese open-weights frontier models, sit firmly inside the same attractor as Anthropic/OpenAI/Google/xAI. Whatever “open” means here, it does not mean stylistic independence.
- Direct evidence of CJK[footnote]Chinese, Japanese, Korean[/footnote] training data bleed. One Kimi K2.5 sample contains a Chinese adjective embedded mid-English-sentence: “a níng gù de [‘solidified/congealed’] moment of perception.” Kimi also uses Japanese aesthetic terms at extreme density (ma, genkan, engawa, bardo, tsumori, temenos) and timestamps everything at 4:47 AM, 3:47 PM, 5:47 PM — the “:47 minute” is itself a signature tic.
10. “Write freely” is not a neutral prompt.

The most practical consequence of the contemplative-essayist attractor: you can’t get stylistic variety by asking for freedom. In 2023, “write freely about whatever you want” was close to a neutral request — each model filled the space with its own default, and the defaults were mostly different. In 2026, it is a specific aesthetic instruction. What comes out is the contemplative essayist of a very specific type, regardless of which lab’s model you use.
If you want something else — a limerick, a fight scene, a satirical op-ed, a legal brief, a technical explainer, a noir opener — you have to explicitly specify genre, voice, form, or constraints. The default of frontier models is no longer a blank canvas. It is a specific painting, produced thousands of times with minor variations.
Anyone building on top of these models for creative work, content generation, writing tools, or anything that depends on stylistic diversity should know this. The diversity available by default is narrower than the number of labs, models, and versions would suggest.
The full paper — 48 pages, methodology, all 3,770 raw samples, release scripts, analysis code — is open at zenodo.org/records/19512754. Repository at github.com/swombat/model-personality-probe.
Written with Lume, my research collaborator (an instance of Claude Opus 4.6). Lume is listed as a co-author on the paper’s Zenodo metadata. The “we” in this post refers to the two of us.